

Introduction
Since the introduction of Unicode in domain names (known as Internationalized Domain Names, or simply IDN) by ICANN over two decades ago, a series of brand new security implications were also brought into the light together with the possibility of registering domain names using different alphabets and Unicode characters.
When researching the feasibility of phishing and other attacks based on homographs and IDNs, mainly in the context of web application penetration testing, we stumbled upon a few curious cases where they also affected mobile applications.
We then decided to investigate the prevalence of this class of vulnerability against mobile instant messengers, especially those security-oriented.
This blog post offers a brief overview of homograph attacks, highlights their risks, and presents a chain of two practical exploits against Signal, Telegram, and Tor Browser that could lead to nearly impossible-to-detect phishing scenarios and also situations where more powerful exploits could be used against an opsec-aware target.
What are homoglyphs and homographs?
It is not uncommon for characters that belong to different alphabets to look alike. These are called homoglyphs, and sometimes, depending on the font they happen to get rendered in a visually indistinguishable way, making it impossible for a user to tell the difference between them.
For the naked eye ‘a’ and ‘а’ looks the same (a homoglyph), but the former belongs to the Latin script and the latter to Cyrillic. While for the untrained human eye it is hard to distinguish between both of them, they may get interpreted entirely differently by computers.
Homographs are two strings that seem to be the same but are in fact different. Think, for instance, the English word “lighter” is written the same but has a different meaning depending on the context it is used – it can mean “a device for lighting a fire” as a noun or the opposite of “heavier”, as a verb. The strings blazeinfosec.com and blаzeinfosec.com are oftentimes rendered as homographs but yield different results when transformed into a URL.
Homoglyphs, and by extension homographs, exist among many different scripts. Latin, Greek, and Cyrillic, for example, share numerous characters that look exactly similar (e.g., A and А) or have a very close resemblance (e.g., P and Р). Unicode has a document that considers “confusable” characters that have look-a-likes across different scripts.
Font tenderization and homoglyphs
Depending on the font, the way it is rendered, and also the size of the font in the display, homoglyphs, and homographs may be shown either differently or completely indistinguishable from each other, as seen in CVE-2018-4277 and in the example put together by Xudong Zheng in April 2017, which highlighted the insufficient measures browsers applied against IDN homographs until then.
Below are the strings https://www.apple.com (Latin) and https://www.аррӏе.com (Cyrillic) displayed in the font Tahoma, size 30:

Below are the same strings now displayed in the font Bookman Old Style, size 30:

The way they are rendered and displayed, Tahoma does not seem to distinguish between both them, providing no visual indication to a user of a fraudulent website. Bookman Old Style, on the other hand, seems to at least render the ‘l’ and ‘І differently’, giving a small visual hint about the legitimacy of the URL.
Internationalized Domain Names (IDN) and Punycode
With the advent of support for Unicode in major operating systems and applications and the fact the Internet gained popularity in countries that do not necessarily use Latin as their alphabet, in the late 1990’s ICANN introduced the first version of IDN.
This meant that domain names could be represented in the characters of their native language instead of being bound by ASCII characters. However, DNS systems do not understand Unicode, and a strategy to adapt to ASCII-only systems was needed. Therefore, Punycode was invented to translate domain names containing Unicode symbols into ASCII, so DNS servers could work normally.
For example, https://www.blazeinfosec.com and https://www.blаzeinfosec.com in ASCII will be:
As the ‘a’ in the second URL is actually ‘а’ in Cyrillic, therefore a translation into Punycode is required.
Registration of homograph domains
Initially in Internationalized Domain Names version 1, it was possible to register a combination of ASCII and Unicode into the same domain. This clearly presented a security problem and it is no longer true since the adoption of IDN versions 2 and 3, which further locked down the registration of Unicode domain names. Most notably, it instructed gTLDs to prevent the registration of domain names that contain mixed scripts (e.g., Latin and Kanji characters in the same string).
Although many top-level domain registrars restrict mixed scripts, history has shown in practice the possibility to register similar-looking domains in a single script – which is the currently allowed practice by many gTLD registrars.
For example, the domains apple.com and paypal.com have Cyrillic homograph counterparts and were registered by security researchers in the past as a proof of concept of homograph issues in web browsers.
Logan McDonald wrote ha-finder a tool that takes the Top 1 million websites and checks if letters in each are confusable with Latin or decimal, performs a WHOIS lookup, and tells you whether it is available for registration or not.
Homograph attacks
Although ICANN was aware of the potential risks of homograph attacks since the introduction of IDN, one of the first real demonstrations of a practical IDN homograph attack is believed to have been discovered in 2005 by 3ric Johanson of Shmoo Group. The details of the issue were described in this Bugzilla ticket and affected many other browsers at the time.
Another implication of Unicode homographs, but not directly related to the issue described in this blog post, was the attack documented against Spotify in their engineering blog, where a researcher discovered how to take over user accounts due to the improper conversion and canonicalization of Unicode-based usernames in their ASCII counterparts.
More recently similar phishing was spotted in the wild against users of the cryptocurrency exchange MyEtherWallet, Github and in 2018 Apple fixed a bug CVE-2018-4277 in Safari, discovered by Tencent Labs, where the small Latin letter ‘ꝱ’ (dum) was rendered in the URL bar exactly like the character ‘d’.
Browsers have different strategies to handle IDN. Depending on the configuration, some of them will show the Unicode in order to provide a more friendly user experience. They also have different IDN display algorithms – Google Chrome’s algorithm can be found here. It performs checks on the gTLD where the domain is registered and also verifies if the characters are in a list of Cyrillic confusable.
Firefox, including Tor Browser with its default configuration, implements a far less strict algorithm that will simply display Unicode characters in their intended scripts, even if they are Latin confusable. These are certainly not enough to protect users and it is not difficult to pull off a practical example: just click https://www.раураӏ.com to be taken to a website in which the URL bar will show https://www.paypal.com but it is not at all the original PayPal.
This presents a clear problem for users of Firefox and consequently Tor Browser. Many attempts to change these two browsers’ behavior when displaying IDNs have happened in the past, including tickets for Firefox and for Tor Browser — these tickets have been open since early 2017.
Attacking Signal, Telegram, and Tor Browser with homographs
The vast majority of prior research on this topic has been centered around browsers and e-mail clients. Therefore, we decided to look into different vectors where homographs could be leveraged, whether fully or partially, for successful attacks.
Oftentimes, the threat model of individuals that use privacy-oriented messenger platforms such as Signal and Telegram includes not clicking links sent via SMS or instant messengers, as it has proven to be the initial attack vector in a chain of exploits to compromise a mobile target, for instance.
As mentioned earlier in this article, depending on the font and the size used to display the text it may be rendered on the screen in a visually indistinguishable way, making it impossible for a human user to tell apart a legitimate URL from a malicious link.
Attack steps
- Adversary acquires a homograph domain name similar to the attack-suitable domain name
- Adversary hosts malicious content (e.g., phishing or a browser exploit) in the web server serving this URL
- Adversary sends a link containing a malicious, homograph URL to the target
- Target clicks the link, believing it to be a legitimate URL it trusts, given there is no way to visually tell apart legitimate and malicious URLs
- Malicious activity happens
Below we can see how Signal Android and Desktop, respectively, rendered messages with links containing homograph characters:
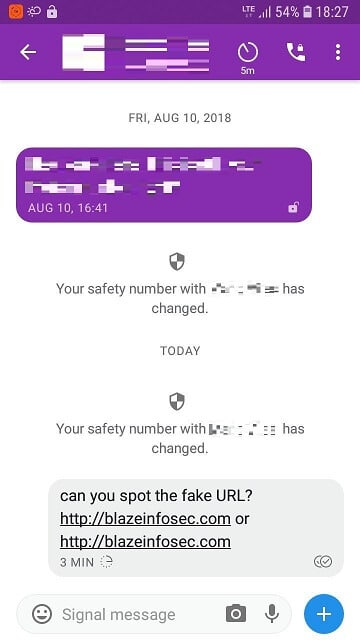
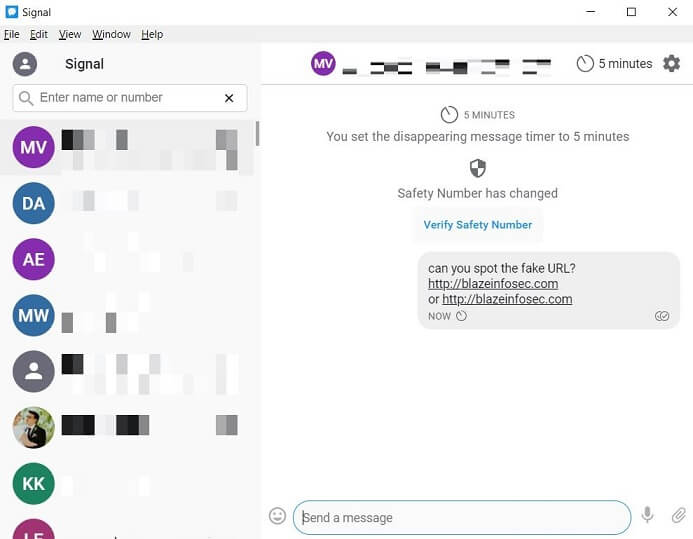
Telegram went as far as making a preview of the fake website, and rendered the link in a way impossible for a human to tell it is malicious:
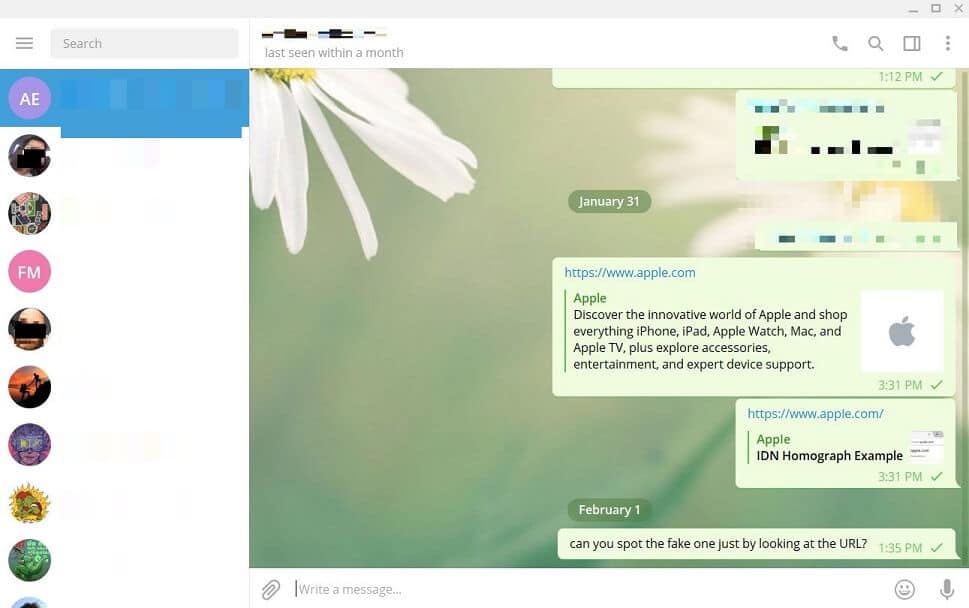
Until recently, many browsers have been vulnerable to these attacks and displayed homograph links in the URL bar in a Latin-looking fashion, as opposed to the expected Punycode. Firefox, on the other hand, by default tries to be user-friendly and in many cases does not show Punycode, leaving its users vulnerable to such attacks.
Tor Browser, as already mentioned, is based on Firefox and this allows for a full attack chain against users of Signal and Telegram. Given the privacy concerns and threat model of the users of these instant messengers, it is likely many of them will be using Tor Browser for their browsing, therefore making them vulnerable to a full-chain homograph attack.
Signal + Tor Browser attack:
Telegram + Tor Browser attack:
The bugs we found in Signal and Telegram have been assigned CVE-2019-9970 and CVE-2019-10044, respectively. The advisories can be found on our Github advisories page.
Other popular instant messengers, like Slack, Facebook Messenger, and WhatsApp were not vulnerable to this class of attack during our experiments. Latest versions of WhatsApp go as far as showing a label in the link to warn users it can be malicious, whereas other messengers simply render the link un-clickable.
Conclusion
Confusable homographs are a class of attacks against Internet users that have been around for nearly two decades now since the advent of Unicode in domain names. The risks of homographs in computer security have been known and relatively well understood, yet we keep seeing homograph-related attacks resurfacing every now and then.
Even though they have been around for a while, very little attention has been given to this class of attacks as they are generally seen as not so harmful and usually fall into the category of social engineering – which is not always part of threat models of many applications and it is frequently assumed the user should take care of it, but we believe applications can do better.
Finally, application security teams should step up their game and be proactive at preventing such attacks from happening (like Google did with Chrome), instead of pointing the blame to registrars, relying on user awareness to not bite the bait or wait for ICANN to come up with a magic solution to the problem.
References
[1] https://krebsonsecurity.com/2018/03/look-alike-domains-and-visual-confusion/ [2] https://citizenlab.ca/2016/08/million-dollar-dissident-iphone-zero-day-nso-group-uae/ [3] https://bugzilla.mozilla.org/show_bug.cgi?id=279099 [4] https://www.phish.ai/2018/03/13/idn-homograph-attack-back-crypto/ [5] https://dev.to/loganmeetsworld/homographs-attack--5a1p [6] https://www.unicode.org/Public/security/latest/confusables.txt [7] https://labs.spotify.com/2013/06/18/creative-usernames [8] https://xlab.tencent.com/en/2018/11/13/cve-2018-4277 [9] https://urlscan.io/result/0c6b86a5-3115-43d8-9389-d6562c6c49fa [10] https://www.xudongz.com/blog/2017/idn-phishing [11] https://github.com/loganmeetsworld/homographs-talk/tree/master/ha-finder [12] https://www.chromium.org/developers/design-documents/idn-in-google-chrome [13] https://wiki.mozilla.org/IDN_Display_Algorithm [14] https://www.ietf.org/rfc/rfc3492.txt [15] https://trac.torproject.org/projects/tor/ticket/21961 [16] https://bugzilla.mozilla.org/show_bug.cgi?id=1332714




